
Welcome to NewsReader: “Building structured event Indexes of large volumes of financial and economic Data for Decision Making”
We built reading machines in 4 languages. Check out this video to meet the Reading Machine!
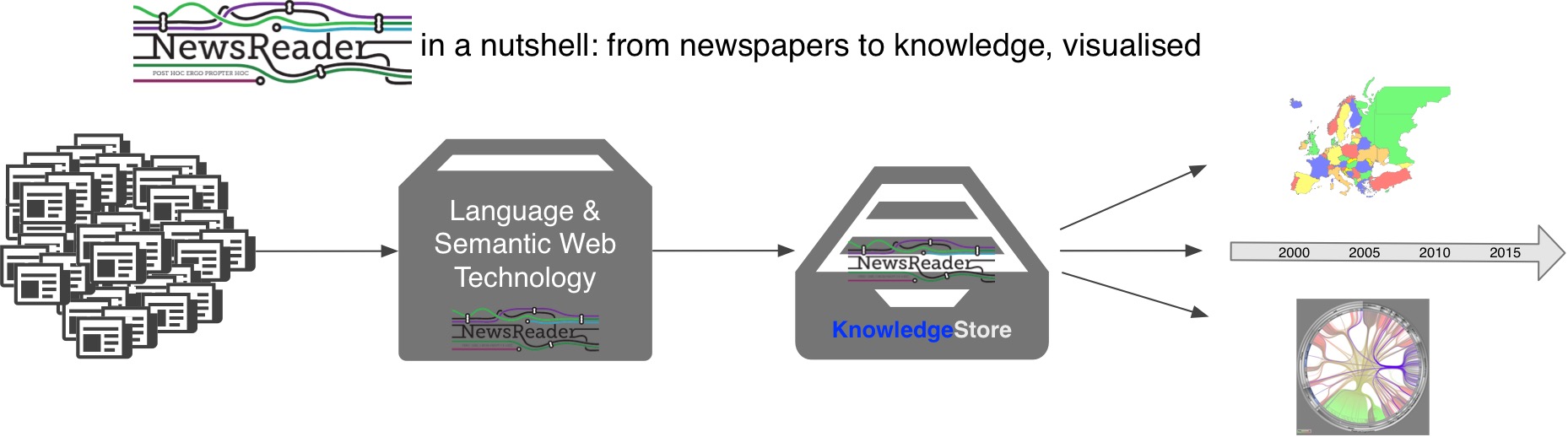
The volume of news data is enormous and expanding, covering billions of archived documents with millions of documents added daily. These documents are also getting more and more interconnected with knowledge from other sources such as biographies and company databases. NewsReader built a system that extracts what happened to whom, when and where from these sources and stores them in a structured database, enabling more precise search over this immense stack of information. Currently, our system supports English, Spanish, Italian and Dutch. Pilot projects are underway with government and financial information specialists, but the system can be useful to anyone looking to make sense of large amounts of news text. A general summary of the project can be found here: NWR-PUBLIC-SUMMARY
Main journal publications:
- P. Vossen, R. Agerri, I. Aldabe, A. Cybulska, M. van Erp, A. Fokkens, E. Laparra, A. Minard, A. P. Aprosio, G. Rigau, M. Rospocher, and R. Segers, “NewsReader: Using knowledge resources in a cross-lingual reading machine to generate more knowledge from massive streams of news”, Special issue knowledge-based systems, elsevier, 2016. [PDF] dx.doi.org/10.1016/j.knosys.2016.07.013, [BibTeX]
- M. Rospocher, M. van Erp, P. Vossen, A. Fokkens, I. Aldabe, G. Rigau, A. Soroa, T. Ploeger, and T. Bogaard, “Building event-centric knowledge graphs from news,” Journal of web semantics, 2016.[BibTeX]
- R. Agerri and G. Rigau, “Robust multilingual named entity recognition with shallow semi-supervised features,” Journal of artificial intelligence, Revised and Resubmitted. [BibTeX]
 |
Contact us to learn more!